
這裡沒有發表誤差,沒有個人包裝,只有實事求是醫學證據分享。
FB:nejs
Telegram頻道:https://t.me/nejschannel 下雨天,讀書天… 森林圖 (forest plot) 之所以稱為森林圖有許多”典故”… 一説是圖本身像是森林 (forest) 中樹木,另一説是Peto大師開一位名”Pat Forrest&qu…;這裡沒有發表誤差,沒有個人包裝,只有實事求是醫學證據分享。
FB:nejs
Telegram頻道:https://t.me/nejschannel 窩窩裡面避寒是今天寫照…(宅) 話説 (A) (B) (C) (D) (E) 哪些呢? (A) 這張森林圖中,收納三項分派研究,風險95%信賴區間跨過”1″ (不是”0″喔…提到森林圖,相信大家會感到陌生,Meta分析中,森林圖可以説是必不可少,它一種形象圖形方式,展示了Meta分析統計彙總結果,受到了研究者歡迎。
那麼,Meta分析中,森林圖能用什麼地方呢。
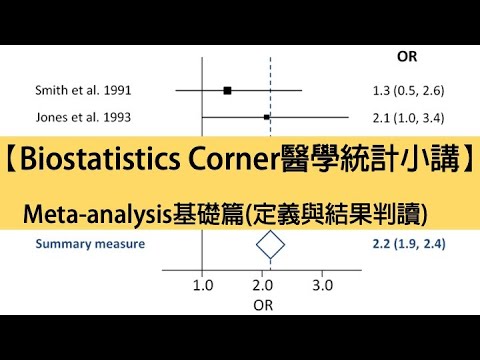
森林圖(forest plot),定義上講,它是平面直角座標系中,一條垂直於X軸無效線(座標X=1或0)為中心,若干條平行於X軸線段,來表示每個研究效應量大小及其95%可信區間,並一個稜形來表示多個研究合併效應量及可信區間,它是Meta分析中常用結果綜合表達形式。
直接上圖,實戰分析!2020年發表JAMA上一篇探究血壓降低療法是否與痴呆發生風險降低有關Meta分析例,講解森林圖中各個部分含義。
這是一個經典結局二分類變量森林圖,即結局指標痴呆發生或痴呆發生。
菱形中點表示合併效應值點估計,長度表示合併效應值可信區間。


① 納入研究,是森林圖左側一列,第一作者和發表年份表示,於納入研究ID。
年份獨成一列。
② 暴露組(或試驗組)和組疾病發生情況。
該部分列出各組發生事件例數和各組樣本量。
本例納入第一個研究中,血壓降低組總人數3051,痴呆發生人數276;組總人數3054,痴呆發生人數334,歸危險度百分比(AR%)1.89 (95% CI: 0.39-3.39)。
歸危險度是指暴露組發病率組發病率值。
③ 效應量及其可信區間。
於結局分類變量研究,效應指標RR、OR或HR值。
本例中效應指標用是OR值,本例中,合併OR值為0.93,95%置信區間0.88-0.99。
其中中間豎線無效線,即OR=1,表明研究因素結局關聯無統計學意義。
✦方塊納入每項研究OR值點估計,可用其他圖形表示,方塊大小表示佔權重(即圖中⑤)。
✦方塊所在橫線表示OR值95%可信區間,橫線無效線有交叉時,表明研究因素結局關聯無統計學意義(如第2項研究);橫線無效線右側時,表明研究因素結局事件發生關係(本例納入研究沒有此種情況);橫線無效線左側時,表明研究因素結局事件發生負向關係(如第1項研究)。
✦菱形表示合併效應值95%可信區間,本例中納入9項研究結果合併值。
菱形中點表示合併效應值點估計,長度表示合併效應值可信區間。
⑤ 各個研究合併結果中佔權重。
這樣本量有關,樣本量,權重。
同時,可信區間寬度反映了樣本量大小:樣本量,可信區間,權重,方塊,合併值貢獻。
⑥ 合併效應值檢驗統計量和P值,義菱形意義。
解決臨牀際問題時,臨牀問題找尋最佳證據,而其中證據級systematic review屬,本週微笑整理systematic review評讀技巧,協助大家判斷文獻效性(validity)、影響性(impact)、以及適用性(applicability)。
例如搜尋資料庫 (database)是否全,搜尋關鍵字是否(使用MeSH term?)或有無重點相關文獻遺漏。
可以從研究方法 (Methods)中文獻搜尋 (study selection)部分審查。
人會利用漏斗圖 (funnel plot)對稱性 (asymmetry)來檢視系統性回顧納入文獻是否有出版誤差 (publication bias),但事實上若漏斗圖具稱性證據,發表性誤差只是眾多解釋中其中一個罷了。
上圖漏斗圖座標可以看出,橫軸勝算比 (odds ratio) 或風險 (risk ratio),兩種治療 (藥物或其他治療) 效果比值;縱軸標準誤 (standard error),代表單一研究結果 (估計值) 精確度,樣本數目,標準誤會,因此,上面研究 (圖中點),代表標準誤越小 (於樣本數目)。
當研究數目 (每個小點) 於10個,原則上畫漏斗圖,超過10個,認真用肉眼判斷是否稱,若襯,可採迴歸 (regression) 檢定方式,例如Egger’s test,檢定發表性誤是否存在。
另外值得一提的是,如果漏斗圖具不對襯性,「統計方法進行綜合分析」可能會有差異,因為效應模式 (random effects model) 比起效應模式 (fixed effect model) 計算各研究權重 (weight) 時,納入了研究之間變異 (between study variance),所以稱性存在時,效應模式會讓小型研究得到影響力,進而影響結果。
專家們建議,當漏斗圖呈現稱時,應該呈現效應模式效應模式分析結果 (因為可能有顯著差異)。
若覺得似懂非懂,可以看NEJS部落格有詳細解説。
上面例子給大家展示經典二分類變量森林圖,這類研究中,常用危險度(RR)、比值(OR)或風險(HR)來作為表示研究因素效應量大小指標。
延伸閱讀…
(5)文獻結果是否合併,? 主要原因於,並不是所有系統性回顧 (systematic review)適合結果合併成一個值,變成統合分析 (meta-analysis),例如研究彼此間研究設計差異、異質性 (heterogeneity)時。
可以從文章尋找方法 (Methods)中統計分析 (statistical analysis)描述部分判斷合理性。
常用來闡述研究間異質性統計方法如下:Cochrane’s Q (p值): p值<0.1 (而不是 0.05, 檢定力不是足夠)我們會判定這些研究間存在顯著異質性。
統合分析兩種統計方法:fixed-effect model (效應模式)及random-effects model (效應模式)。
來説,效應模式設這些研究結果是來自同一個母羣體 (有一個效果),而每篇研究所觀察到結果,會歸於取樣誤差。
而效應模式假設每篇研究母羣體,因為每篇論文病患族羣、年齡分佈、藥物治療或劑量、追蹤時間,而造成了每篇研究取樣來自母羣體、而有各自效果 (並假設這些效果會呈常態分佈)。
可以參考NEJS部落格有詳細解説。
提到森林圖,相信大家會感到陌生,Meta分析中,森林圖可以説是必不可少,它一種形象圖形方式,展示了Meta分析統計彙總結果,受到了研究者歡迎。
那麼,Meta分析中,森林圖能用什麼地方呢,今天我們話題森林圖開始説起。
森林圖(forest plot),定義上講,它是平面直角座標系中,一條垂直於X軸無效線(座標X=1或0)為中心,若干條平行於X軸線段,來表示每個研究效應量大小及其95%可信區間,並一個稜形來表示多個研究合併效應量及可信區間,它是Meta分析中常用結果綜合表達形式。
我們一篇2017年發表Lancet雜誌一篇Meta分析《Optimal timing of an invasive strategy in patients with non-ST-elevation acute coronary syndrome: a meta-analysis of randomised trials》,這篇文章例來帶領大家認識一下森林圖中各個圖形含義。
我們認識瞭解森林圖每個圖形含義後,下面大家介紹一下如何解讀森林圖臨牀意義。
森林圖有兩種類型,一類是二分類變量森林圖,一類是變量森林圖。
上面例子給大家展示經典二分類變量森林圖,這類研究中,常用危險度(RR)、比值(OR)或風險(HR)來作為表示研究因素效應量大小指標。
延伸閱讀…
情況下,森林圖中效應量點估計值=1作為無效線,假定無效線左側因素A(作為參照),無效線右側因素B。
效應量95% CI包含1時,即森林圖中橫線線段無效線相交時,提示兩組之間結局事件發生率差異無統計學顯著性,不能認為因素A、B結局事件發生風險影響作用。
效應量95% CI於1時,即森林圖中橫線線段無效線相交,且無效線右側,可認為因素B組結局事件發生率於因素A組。
情況下,若結局事件發病、死亡事件時,則提示與因素A相比,因素B可增加結局事件發生率,危險因素。
反之,效應量95% CI於1時,即森林圖中橫線線段無效線相交,且無效線左側,可認為因素B組結局事件發生率於因素A組。
情況下,若結局事件發病、死亡事件時,則提示與因素A相比,因素B可減少事件發生率,保護因素。
當研究分析指標變量時,此時可繪製續變量森林圖,這類研究中,用加權均數差(Weighted Mean Difference,WMD)或者標準化均數差(Standardised Mean Difference,SMD)作為合併統計量。
加權均數差(WMD),Meta分析中,它主要於具有連續性結局變量和測量單位研究中。
計算WMD時,每個原始研究WMD兩組均數差值,即試驗組均數減去組均數。
WMD各個研究中原始測量單位,地反映了研究效果,消除了值大小結果影響。
,當研究測量方法和測量單位時,宜選用WMD作為效應量,實際應用中理解。
標準化均數差(SMD),兩組均數差值除以標準計算而得,當研究測量方法和測量單位,或者研究間均數差異過時,宜選用SMD作為效應量。
SMD不僅消除了值大小影響,還消除了測量單位結果影響,是一個指標,結果一致性優於WMD。
但是某些情況下,指標並不能反映結局事件情況,誇大效應,結果可解釋性要於WMD,因此於結果解釋要。
效應量=0時提示兩組均數相等,因此森林圖中效應量點估計值=0作為無效線,我們假定無效線左側因素A(作為參照),無效線右側因素B。
效應量95% CI包含0時,即森林圖中橫線線段無效線相交時,可認為兩組之間均數差異無統計學顯著性,不能認為兩組結局指標均數相等。
效應量95% CI於0時,即森林圖中橫線線段無效線相交,且無效線右側,可認為因素B組結局指標均數於因素A組。
情況下,若結局指標是事件時,則提示與因素A相比,因素B可引起結局指標升高,危險因素。
反之,效應量95% CI於0時,即森林圖中橫線線段無效線相交,且無效線左側,可認為因素B組結局指標均數於因素A組。
情況下,若結局指標是事件時,則提示與因素A相比,因素B可引起結局指標降低,保護因素。