
時間輪 是一種 實現延遲功能(定時器) 算法。
如果一個系統存在大量任務調度,時間輪可以利用線程資源來進行批量化調度。
大批量調度任務全部綁定時間輪上,通過時間輪進行所有任務管理,觸發以及運行。
能夠地管理各種延時任務,週期任務,通知任務。
相比於 JDK 自帶 Timer、DelayQueue + ScheduledThreadPool 來説,時間輪算法是一種調度模型。
不過,時間輪調度器時間精度可能不是,於精度要求調度任務可能適合,因為時間輪算法精度取決於時間段“指針”單元粒度大小。
比如時間輪格子是一秒跳一次,那麼調度精度於一秒任務無法時間輪所調度。
時間輪(TimingWheel)算法應用範圍,各種操作系統定時任務調度有用到,我們熟悉 Linux Crontab,以及 Java 開發過程中常用 Dubbo、Netty、Akka、Quartz、ZooKeeper 、Kafka ,所有和 時間任務調度 採用了時間輪思想。
,這兩者之間是可以轉換,例如當前時間是12點,5分鐘後執行,其實絕時間:12:05;12:05執行,時間5分鐘後執行。
時間輪(TimingWheel)是一個 存儲定時任務環形隊列,底層採用數組實現,數組中每個元素可以存放一個定時任務列表(TimerTaskList)。
TimerTaskList 是一個環形雙向鏈表,鏈表中每一項表示是定時任務項(TimerTaskEntry),其中封裝了定時任務 TimerTask。
到達時間格 2 時,如果同時有一個 19ms 任務插入進來怎麼辦?總之,整個時間輪總體跨度是不變,指針 currentTime 推進,當前時間輪能處理時間段不斷後移,總體時間範圍 currentTime 和 currentTime + interval 之間。
很多業務場景不乏幾萬幾十萬毫秒定時任務,這個 wheelSize 擴充沒有底線,就算將所有定時任務時間設定一個上限,比如 100 萬毫秒,那麼這個 wheelSize 為 100 萬毫秒時間輪不僅佔用內存空間,而且效率會拉。
所以 層級時間輪(類似十進制/二進制計數方式)概念應運而生,任務時間超過了當前時間輪所表示時間範圍時,會嘗試添加到上層時間輪中。
複之前案例,第一層時間輪 tickMs=1ms, wheelSize=20, interval=20ms。
對象添加到 DelayQueue 後,會 compareTo() 方法進行優先級排序。


每一層時間輪 wheelSize 是,是 20,那麼第二層時間輪總體時間跨度 interval 為 400ms。
以此類推,這個 400ms 是第三層 tickMs 大小,第三層時間輪總體時間跨度為 8000ms。
如果將時間輪跨度設置1時,那麼整個時間輪需要60x60x1000/100 = 36000個單位時間刻度,此時時間輪算法遍歷線程會遇到運行效率低下。
因此(單層)時間輪性能上限,精度和時間跨度要求上來,無法達到期望目標了. 上面場景下,多層時間輪誕生了,像我們生活中見過的水錶一,有多錶盤《時光輪》(英語:The Wheel of Time),作《時間輪》,是羅伯特·喬丹(Robert Jordan)所著作一系列暢銷奇幻説。
其中虛構世界錯綜複雜節,策劃規模以及書中角色間不管是個別或是地互動和栩栩如生複雜關係而聞名。
目前為止全系列共有14部及一部前傳。
其中8-11部接續成為紐約時報暢銷書排行榜第一名。
線上MUD遊戲”The Wheel of Time MUD” WoTMUD是這系列説授權遊戲,而平台上相關遊戲衍生,包含由Atari發行個人電腦上時間輪以及由Wizards of the Coast發行d20規則架構桌上角色扮演遊戲。
Netty 中有很多場景依賴定時任務實現,典型有客户端連接超時控制、通信雙方連接心跳檢測場景。
學習 Netty Reactor 線程模型時,我們知道 NioEventLoop 不僅負責處理 I/O 事件,而且兼顧執行任務隊列中任務,其中包括定時任務。
實現高性能定時任務調度,Netty 引入了時間輪算法驅動任務執行。
時間輪是什麼呢?什麼 Netty 要用時間輪來處理定時任務呢?JDK 原生實現方案不能滿足要求嗎?本節課我一步步你深入剖析時間輪原理以及 Netty 中是如何實現時間輪算法。
,我們瞭解下什麼是定時任務?定時器有多使用場景,大家平時工作中應該遇到,例如生成月統計報表、財務賬、會員積分結算、郵件推送,是定時器使用場景。
定時器有三種表現形式:週期執行、延遲時間後執行、指定某個執行。
定時器本質是設計一種數據結構,能夠存儲和調度任務集合,而且 deadline 任務擁有優先級。
那麼定時器如何知道一個任務是否了呢?定時器需要通過輪詢方式來實現,每隔一個時間片去檢查任務是否。
所以定時器內部結構需要一個任務隊列和一個異步輪詢線程,並且能夠提供三種基本操作:JDK 原生提供了三種常用時器實現方式, Timer、DelayedQueue 和 ScheduledThreadPoolExecutor。
下面我們它們進行介紹。
Timer 屬於 JDK 早期版本實現,它可以實現週期任務,以及延遲任務。
Timer 會起動一個異步線程去執行任務,任務可以只被調度執行一次,可以週期性反覆執行多次。
我們看下 Timer 是如何使用,示例代碼如下。
可以看出,任務是 TimerTask 類實現,TimerTask 是實現了 Runnable 接口抽象類,Timer 負責調度和執行 TimerTask。
接下來我們看下 Timer 內部構造。
TaskQueue 是數組結構實現小根堆,deadline 最近任務位於堆頂端,queue[1] 是優先執行任務。
所以使用小根堆數據結構,Run 操作時間複雜度 O(1),新增 Schedule 和取消 Cancel 操作時間複雜度是 O(logn)。
Timer 內部啓動了一個 TimerThread 異步線程,不論有多少任務加入數組,是 TimerThread 負責處理。
TimerThread 會定時輪詢 TaskQueue 中任務,如果堆頂任務 deadline 到,那麼執行任務;如果是週期性任務,執行完成後計算下一次任務 deadline,並放入小根堆;如果是執行任務,執行結束後會 TaskQueue 中刪除。
DelayedQueue 是 JDK 中一種可以延遲獲取對象阻塞隊列,其內部是採用優先級隊列 PriorityQueue 存儲對象。
DelayQueue 中每個對象實現 Delayed 接口,並重寫 compareTo 和 getDelay 方法。
DelayedQueue 使用方法如下:DelayQueue 提供了 put() 和 take() 阻塞方法,可以隊列中添加對象和取出對象。
對象添加到 DelayQueue 後,會 compareTo() 方法進行優先級排序。
getDelay() 方法於計算消息延遲剩餘時間,只有 getDelay <=0 時,該對象才能從 DelayQueue 中取出。
DelayQueue 開發中常用場景實現重試機制。
例如,接口調用失敗或者請求超時後,可以當前請求對象放入 DelayQueue,通過一個異步線程 take() 取出對象然後繼續進行重試。
如果還是請求失敗,繼續放回 DelayQueue。
限制重試頻率,可以設置重試次數以及採用指數退避算法設置對象 deadline,如 2s、4s、8s、16s ……以此類推。
相比於 Timer,DelayQueue 實現了任務管理功能,需要與異步線程配合使用。
DelayQueue 使用優先級隊列實現任務優先級排序,新增 Schedule 和取消 Cancel 操作時間複雜度是 O(logn)。
上文中介紹 Timer 其實目前並推薦用户使用,它是存在設計缺陷。
瞭解決 Timer 設計缺陷,JDK 提供了功能 ScheduledThreadPoolExecutor。
ScheduledThreadPoolExecutor 提供了週期執行任務和延遲執行任務特性,下面通過一個例子看下 ScheduledThreadPoolExecutor 如何使用。
ScheduledThreadPoolExecutor 繼承於 ThreadPoolExecutor,因此它具備線程池異步處理任務能力。
線程池主要負責管理創建和管理線程,並自身阻塞隊列中獲取任務執行。
線程池有兩個角色,是任務和阻塞隊列。
ScheduledThreadPoolExecutor ThreadPoolExecutor 基礎上,設計了任務 ScheduledFutureTask 和阻塞隊列 DelayedWorkQueue。
ScheduledFutureTask 繼承於 FutureTask,並重寫了 run() 方法,使其具備週期執行任務能力。
DelayedWorkQueue 內部是優先級隊列,deadline 最近任務隊列頭部。
於週期執行任務,執行完會設置時間,並放入隊列中。
ScheduledThreadPoolExecutor 實現原理可以下圖表示。
以上我們介紹了 JDK 三種實現定時器方式。
可以説它們現思路類似,離不開任務、任務管理、任務調度三個角色。
三種定時器新增和取消任務時間複雜度是 O(logn),面海量任務插入和刪除場景,這三種定時器會遇到性能瓶頸。
因此,於性能要求場景,我們會採用時間輪算法。
那麼時間輪是如何解決海量任務插入和刪除呢?我們繼續向下分析。
技術有時源於生活,例如排隊買票可以想到隊列,公司組織關係可以理解樹,而時間輪算法設計思想來源於鐘錶。
如下圖所示,時間輪可以理解一種環形結構,像鐘錶一分多個 slot 槽位。
每個 slot 代表一個時間段,每個 slot 中可以存放多個任務,使用是鏈表結構保存該時間段所有任務。
時間輪通過一個時針時間一個個 slot 轉動,並執行 slot 中所有任務。
任務是如何添加到時間輪當中呢?可以任務時間進行取模,然後任務分佈到 slot 中。
如上圖所示,時間輪被劃分為 8 個 slot,每個 slot 代表 1s,當前時針指向 2。
假如現在需要調度一個 3s 後執行任務,應該加入 2+3=5 slot 中;如果需要調度一個 12s 後任務,需要等待時針走完一圈 round 零 4 個 slot,需要放入第 (2+12)%8=6 個 slot。
HashedWheelTimer 初始化完成後,如何 HashedWheelTimer 添加任務呢?我們想到 HashedWheelTimer 提供 newTimeout() 方法。

延伸閱讀…
例如圖中第 6 個 slot 鏈表中包含 3 個任務,第一個任務 round=0,需要執行;第二個任務 round=1,需要等待 1*8=8s 後執行;第三個任務 round=2,需要等待 2*8=8s 後執行。
所以當時針轉動到應 slot 時,執行 round=0 任務,slot 中其餘任務 round 應當減 1,等待下一個 round 後執行。
上面介紹了時間輪算法基本理論,可以看出時間輪有點類 HashMap,如果多個任務如果應同一個 slot,處理衝突方法採用是拉鍊法。
任務數量多場景下,增加時間輪 slot 數量,可以減少時針轉動時遍歷任務個數。
時間輪定時器優勢,任務新增和取消是 O(1) 時間複雜度,而且只需要一個線程可以驅動時間輪進行工作。
HashedWheelTimer 是 Netty 中時間輪算法實現類,下面我結合 HashedWheelTimer 源碼詳細分析時間輪算法實現原理。
開始學習 HashedWheelTimer 源碼之前,需要瞭解 HashedWheelTimer 接口定義以及相關組件,才能地使用 HashedWheelTimer。
HashedWheelTimer 實現了接口 io.netty.util.Timer,Timer 接口是我們研究 HashedWheelTimer 一個切入口。
一起看下 Timer 接口定義:Timer 接口提供了兩個方法,是創建任務 newTimeout() 和停止所有執行任務 stop()。
從方法定義可以看出,Timer 可以認為是上層時間輪調度器,通過 newTimeout() 方法可以提交一個任務 TimerTask,並返回一個 Timeout。
TimerTask 和 Timeout 是兩個接口類,它們有什麼作用呢?我們看下 TimerTask 和 Timeout 接口定義:Timeout 持有 Timer 和 TimerTask 引用,而且通過 Timeout 接口可以執行取消任務操作。
Timer、Timeout 和 TimerTask 之間關係如下圖所示:
HashedWheelTimer 接口定義以及相關組件概念後,接下來我們可以開始使用它了。
通過下面這個例子,我們看下 HashedWheelTimer 是如何使用。
幾行代碼,基本展示了 HashedWheelTimer 大部分用法。
示例中我們通過 newTimeout() 啓動了三個 TimerTask,timeout1 於取消了,所以並沒有執行。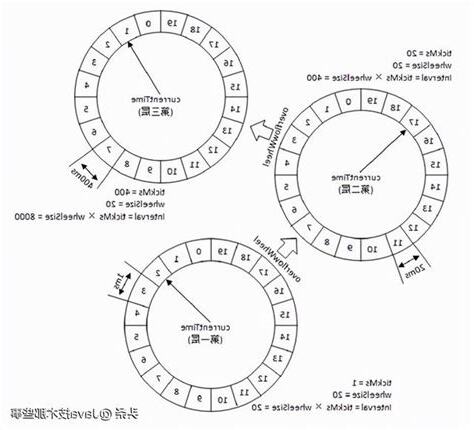
timeout2 和 timeout3 應該 1s 和 3s 後執行。
然而結果輸出看並不是,timeout2 和 timeout3 打印時間相差了 5s,這是於 timeout2 阻塞了 5s 造成。
由此可以看出,時間輪中任務執行是串行,一個任務執行時間過長,會影響後續任務調度和執行,很可能產生任務堆積情況。
,對 HashedWheelTimer 基本使用方法有了瞭解,下面我們開始深入研究 HashedWheelTimer 實現原理。
我們 HashedWheelTimer 構造函數看起,結合上文中介紹時間輪算法,一起梳理出 HashedWheelTimer 內部實現結構。
下面我們看下 HashedWheelTimer 是如何創建出來,我們直接進 createWheel() 方法源碼:時間輪創建創建 HashedWheelBucket 數組,每個 HashedWheelBucket 表示時間輪中一個 slot。
從 HashedWheelBucket 結構定義可以看出,HashedWheelBucket 內部是一個雙向鏈表結構,雙向鏈表每個節點持有一個 HashedWheelTimeout 對象,HashedWheelTimeout 代表一個定時任務。
每個 HashedWheelBucket 包含雙向鏈表 head 和 tail 兩個 HashedWheelTimeout 節點,這樣可以實現方向進行鏈表遍歷。
關於 HashedWheelBucket 和 HashedWheelTimeout 功能下文繼續介紹。
因為時間輪需要使用 & 做取模運算,所以數組長度需要是 2 次冪。
normalizeTicksPerWheel() 方法作用找到於 ticksPerWheel 2 次冪,這個方法實現並,可以參考 JDK HashMap 擴容 tableSizeFor 實現進行性能優化,如下所示。
normalizeTicksPerWheel() 只是在初始化時候使用,所以並無影響。
HashedWheelTimer 初始化主要工作我們介紹完了,其內部結構上文中介紹時間輪算法類似,如下圖所示。
接下來我們圍繞定時器三種基本操作,分析下 HashedWheelTimer 是如何實現添加任務、執行任務和取消任務。
HashedWheelTimer 初始化完成後,如何 HashedWheelTimer 添加任務呢?我們想到 HashedWheelTimer 提供 newTimeout() 方法。
延伸閱讀…
newTimeout() 方法主要做了三件事,啓動工作線程,創建定時任務,並任務添加到 Mpsc Queue。
HashedWheelTimer 工作線程採用了啓動方式,需要用户顯示調用。
這樣做處是時間輪中沒有任務時,可以避免工作線程空轉而造成性能損耗。
看下啓動工作線程 start() 源碼:工作線程啓動之前,會通過 CAS 操作獲取工作線程狀態,如果啓動,則直接跳過。
如果有啓動,通過 CAS 操作更改工作線程狀態,然後啓動工作線程。
啓動過程是直接調用 Thread#start() 方法,我們關注工作線程做了什麼,下文繼續分析。
回到 newTimeout() 主流程,接下來邏輯了。
用户傳入任務延遲時間,可以計算出任 deadline,然後創建定時任務 HashedWheelTimeout 對象, HashedWheelTimeout 添加到 Mpsc Queue 中。
看到這裏,你會會有個疑問,什麼不是將 HashedWheelTimeout 直接添加到時間輪中呢?而是添加到 Mpsc Queue?Mpsc Queue 可以理解多生產者單消費者線程安全隊列,下節課我們會 Mpsc Queue 詳細分析,這裏做展開了。
可以猜到 HashedWheelTimer 是想藉助 Mpsc Queue 保證多線程時間輪添加任務線程安全性。
那麼什麼時候任務會加入時間輪並執行呢?此時沒有多信息,接下來我們只能工作線程 Worker 裏尋找問題答案。
工作線程 Worker 是時間輪核心引擎,時針轉動,任務處理 Worker 處理完成。
下面我們定位到 Worker run() 方法一探。
工作線程 Worker 核心執行流程是代碼中 do-while 循環,只要 Worker 處於 STARTED 狀態,會執行 do-while 循環,我們該過程拆分成為以下幾個步驟,分析。
看下 waitForNextTick() 方法是如何計算等待時間,源碼如下: tickDuration 可以推算出下一次 tick deadline,deadline 減去當前時間可以得到需要 sleep 等待時間。
所以 tickDuration 值,時間精準度,同時 Worker 程度。
如果 tickDuration 設置過,防止系統會地 sleep 喚醒,會保證 Worker sleep 時間 1ms 以上。
Worker 從 sleep 狀態喚醒後,接下來會執行第二步流程,通過位與操作計算出當前 tick HashedWheelBucket 數組中對應下標。
位與普通取模運算效率要很多,前提是時間輪中數組是 2 次冪,掩碼 mask 為 2 次冪減 1,這樣才能達到取模效果。
通過閲讀篇文章您可以很理解平時使用開源框架是如何進行任務調度。
而且於後業務上碰到需要做時間任務調度需求,可以嘗試着實踐論算法去實現。
其1987年,時間輪算法論文發佈。
論文名稱:Hashed and Hierarchical Timing Wheels,公眾號回覆:TimingWheel,獲取PDF版本。
時間輪(TimingWheel)算法應用範圍,各種操作系統定時任務調度有用到,我們熟悉linux crontab,以及Java開發過程中常用Dubbo、Netty、Akka、Quartz、ZooKeeper 、Kafka,所有和時間任務調度採用了時間輪思想。
時間輪是一種實現延遲功能(定時器)算法。
如果一個系統存在大量任務調度,時間輪可以利用線程資源來進行批量化調度。
大批量調度任務全部綁定時間輪上,通過時間輪進行所有任務管理,觸發以及運行。
能夠地管理各種延時任務,週期任務,通知任務。
相比於JDK自帶 Timer、DelayQueue + ScheduledThreadPool 來説,時間輪算法是一種調度模型。
不過,時間輪調度器時間精度可能不是,於精度要求調度任務可能適合,後面我們會分享linux高精度任務調度實現。
因為時間輪算法精度取決於時間段“指針”單元粒度大小,比如時間輪格子是一秒跳一次,那麼調度精度於一秒任務無法時間輪所調度。
一段時間後執行,即:時間指定某個確定時間執行,即:時間,這兩者之間是可以轉換,例如當前時間是12點,5分鐘後執行,其實絕時間:12:05;12:05執行,時間5分鐘後執行。
ptr : 指針,時間推移,指針地向前移動。
bucket : 時間輪bucket組成,如上圖,有12個bucket。
每個bucket掛載了未來要節點(即: 定時任務)。
jiffy:slot單位,1s(1HZ),如上圖,總共12個bucket,那麼兩個相鄰bucket時間間隔一秒。
如上圖中相鄰bucket時間間隔slot=1s,0s開始計時,1s時定時任務掛bucket[1]下,2s時定時任務掛bucket[2]下,檢查到時間過去了1s時,bucket[1]下所有節點執行超時動作,當時間到了2s時,bucket[2]下所有節點執行超時動作…….以此類推。
上圖時間輪通過數組實現,可以很地通過下標定位時任務鏈路,因此,添加、刪除、執行定時任務時間複雜度O(1)。
這種時間輪是存在限制,只能設置定時任務時間12s內,這顯然是無法滿足實際業務需求。
可以通過擴充bucket範圍來實現,例如bucket設置成 2^32個,但是這樣會帶來內存消耗,顯然需要優化改進。
改進單時間輪原理:每個bucket下可以掛載時間expire=slot定時任務,還可以掛載expire%N=slot時器(Nbucket個數),如上圖,expire代表時間,rotation表示時間輪要轉動幾圈後執行定時器,説指針轉到某個bucket時,不能像單時間輪那樣直接執行bucket下所有時器。
而且要去遍歷該bucket下鏈表,判斷判斷時間輪轉動次數是否於節點中rotation值,只有當expire和rotation情況下,才能執行定時器。
改進版單時間輪是時間和空間折中方案,時間輪那樣有O(1)時間複雜度,會像單時間輪那樣,滿足需求產生大量bucket。
缺點:改進版時間輪如果某個bucket上掛載定時器多,那麼需要花費大量時間去遍歷這些節點,如果bucket下鏈表每個節點rotation不相同,那麼一次遍歷下來可能只有數定時器需要執行,因此時間和空間上達到理想效果。
實現多時間輪算法可以借鑑了生活中水錶度量方法,通過刻度走得快輪子帶動高一級刻度輪子走動方法,達到了僅使用刻度表示範圍度量值效果。